ほぼ 3 年間、リャザン高等空挺学校はアナトリーによって指揮されてきました...

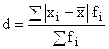
平均値を決定します。
モード (Mo) =11、なぜなら このオプションは、バリエーション シリーズで最も頻繁に発生します (p = 6)。
中央値 (Me) - 中央の位置を占めるバリアントの序数 = 23、変動系列のこの位置は 11 に等しいバリアントによって占められます。算術平均 (M) を使用すると、最も完全に特徴づけることができます。 平均レベル研究中の特性。 算術平均を計算するには、算術平均法とモーメント法という 2 つの方法が使用されます。
変動系列内の各オプションの出現頻度が 1 に等しい場合、単純算術平均は算術平均法 M = を使用して計算されます。
バリエーション系列内のバリエーションの出現頻度が 1 と異なる場合、加重算術平均は算術平均法を使用して計算されます。
モーメント法によると、A - 条件付き平均、
M = A + =11 += 10.4 d=V-A、A=Mo=11
バリエーション シリーズのオプションの数が 30 を超える場合、グループ化されたシリーズが構築されます。 グループ化されたシリーズの構築:
1)VminおよびVmaxの決定Vmin=3、Vmax=20。
2)グループ数の決定(表による)。
3) グループ間の間隔の計算 私 = 3;
4) グループの始まりと終わりを決定する。
5)各グループの変異の頻度の決定(表2)。
表2
グループ化されたシリーズを構築するための方法論
|
間隔 数日で治療 |
|||||||
|
n=45 p=480 p=30 2 p=766 |
グループ化されたバリエーション シリーズの利点は、研究者がすべてのオプションを使用するのではなく、各グループの平均的なオプションのみを使用することです。 これにより、平均の計算が大幅に簡素化されます。
特定の特性の値は、相対的に均一であるにもかかわらず、母集団のすべてのメンバーで同じではありません。 統計的母集団のこの特徴は、一般母集団のグループ特性の 1 つによって特徴付けられます。 特性の多様性。 たとえば、12 歳の少年のグループを取り上げ、身長を測定してみましょう。 計算後、この特性の平均レベルは 153 cm になります。ただし、平均は研究対象の特性の一般的な尺度を特徴付けます。 特定の年齢の少年の中には、身長が 165 cm または 141 cm の少年がいます。153 cm 以外の身長を持つ少年が増えるほど、統計上の母集団におけるこの特性の多様性は大きくなります。
統計により、次の基準によってこのプロパティを特徴付けることができます。
限界 (lim)、
振幅(アンプ)、
標準偏差 (や) ,
変動係数 (Cv)。
限界変動系列内の変動の極値によって決定されます。
lim=V min /V max
振幅 (アンプ) -極端なオプション間の違い:
アンプ=V max -V min
これらの値は、極端な変異の多様性のみを考慮しており、その内部構造を考慮して、集合体における形質の多様性に関する情報を取得することはできません。 したがって、これらの基準は、特に少数の観測値 (n<30).
バリエーションシリーズの医療統計
変化範囲(または変化の範囲) -これは特性の最大値と最小値の差です。
この例では、労働者のシフト生産量の変動範囲は次のとおりです。第 1 旅団では R = 105-95 = 10 人の子供、第 2 旅団では R = 125-75 = 50 人の子供です。 (5倍以上)。 これは、第 1 旅団の生産量がより「安定」していることを示唆していますが、第 2 旅団には生産量を増加させるための余力がより多くあります。 すべての作業員がこの旅団の最大生産量に達した場合、3 * 125 = 375 個の部品を生産できますが、第 1 旅団では 105 * 3 = 315 個の部品しか生産できません。
特性の極値が母集団にとって一般的でない場合は、四分位または十分位の範囲が使用されます。 四分位範囲 RQ= Q3-Q1 は人口体積の 50% をカバーし、最初の十分位範囲 RD1 = D9-D1 はデータの 80% をカバーし、2 番目の十分位範囲 RD2= D8-D2 – 60% をカバーします。
変動範囲インジケーターの欠点は、その値が形質のすべての変動を反映していないことです。
特性のすべての変動を反映する最も単純な一般的な指標は次のとおりです。 平均線形偏差、これは、個々のオプションの平均値からの絶対偏差の算術平均です。
,
グループ化されたデータの場合 ![]() ,
,
ここで、xi は離散系列の属性の値、または区間分布の区間の中央値です。
上記の式では、分子の差は法で計算されます。そうでない場合、算術平均の特性に従って、分子は常に 0 に等しくなります。 したがって、平均線形偏差は統計の実践ではめったに使用されず、符号を考慮せずに指標を合計することが経済的に意味がある場合にのみ使用されます。 これを利用して、たとえば、労働力の構成、生産の収益性、対外貿易売上高などが分析されます。
形質の差異は、平均値からの偏差の平均二乗です。
単純な分散 ![]() ,
,
分散加重  .
.
分散の計算式は次のように簡略化できます。
したがって、分散は、選択肢の二乗平均と母集団の選択肢の平均の二乗の差に等しくなります。  .
.
ただし、偏差の二乗の合計により、分散は偏差についての歪んだ概念を与えるため、平均はそれに基づいて計算されます。 標準偏差これは、特性の特定のバリアントが平均値からどれだけ逸脱しているかを示します。 分散の平方根を計算して計算します。
グループ化されていないデータの場合  ,
,
バリエーションシリーズ用 
分散と標準偏差の値が小さいほど、母集団が均一になり、平均値の信頼性 (典型的) が高くなります。
平均線形偏差と標準偏差は名前付きの数値です。つまり、これらは特性の測定単位で表され、内容は同一で、意味も似ています。
テーブルを使用して絶対変動を計算することをお勧めします。
表 3 - 変動特性の計算 (チーム ワーカーのシフト生産量に関するデータの期間の例を使用)
従業員数 |
インターバルの真ん中 |
計算値 |
|||||
合計: |
|||||||
労働者の平均シフト生産量: ![]()
平均線形偏差: ![]()
生産差異: 
平均生産量からの個々の労働者の生産量の標準偏差:
.
分散の計算には面倒な計算が必要です (特に平均が小数点以下数桁の大きな数値として表される場合)。 簡略化された式と分散特性を使用することで、計算を簡素化できます。
分散液には次の特性があります。
 ,
,
 、その後、または
、その後、または 
分散の特性を使用し、まず母集団のすべての変異を値 A で減らし、次に間隔 h の値で割ることで、等間隔の変異系列の分散を計算する式を取得します。 ある意味: ,
,
ここで、分散はモーメント法を使用して計算されます。
h – 変動系列の間隔の値。
– 新しい(変換された)値のオプション;
A は定数値であり、最高周波数の間隔の中央として使用されます。 または最も頻度が高いオプション。 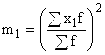 – 一次モーメントの二乗。
– 一次モーメントの二乗。
– 二次命令の瞬間。
チームの従業員のシフト生産量に関するデータに基づいて、モーメント法を使用して分散を計算してみましょう。
表 4 - モーメント法を使用した分散の計算
生産労働者のグループ、PC。 |
従業員数 |
インターバルの真ん中 |
計算値 |
||
計算手順:


統計によって研究される特性の中には、相互に排他的な 2 つの意味しか持たない特性もあります。 これらは代替標識です。 これらにはそれぞれ、オプション 1 と 0 の 2 つの定量値が与えられます。p で示されるオプション 1 の頻度は、この特性を持つユニットの割合です。 差 1-р=q はオプション 0 の頻度です。したがって、
西 |
|
代替符号の算術平均 ![]() なぜなら、p+q=1だからです。
なぜなら、p+q=1だからです。
代替形質の差異
、 なぜなら 1-р=q
したがって、代替特性の分散は、この特性を持つユニットの割合とこの特性を持たないユニットの割合の積に等しくなります。
値 1 と 0 が同じ頻度で発生する場合、つまり p=q の場合、分散は最大 pq=0.25 に達します。
代替属性の分散は、製品品質などのサンプル調査で使用されます。
分散は、他の変動特性とは異なり、追加的な量です。 つまり、要素の特性に従ってグループに分割された集合体です。 バツ , 得られる特性の分散 yは、各グループ内の分散(グループ内)とグループ間(グループ間)の分散に分解できます。 次に、集団全体にわたる形質の変動を研究するとともに、各グループ内の変動、およびこれらのグループ間の変動を研究することが可能になります。
合計差異形質の変動を測定する でこの変動(偏差)を引き起こしたすべての要因の影響下で全体が変化します。 属性の個別値の平均二乗偏差に等しい で総平均から計算され、単純分散または加重分散として計算できます。
グループ間分散結果として得られる形質の変化を特徴付ける で因子記号の影響によって引き起こされる バツ、グループ化の基礎を形成しました。 これはグループ平均のばらつきを特徴づけるもので、全体の平均からのグループ平均の偏差の平均二乗に等しくなります。  ,
,
ここで、 は i 番目のグループの算術平均です。
– i 番目のグループのユニット数 (i 番目のグループの周波数)。
– 母集団全体の平均。
グループ内分散ランダムな変動、つまり説明されていない要因の影響によって引き起こされ、グループ化の基礎を形成する要因属性に依存しない変動の部分を反映します。 これは、グループ平均に対する個々の値の変動を特徴づけるものであり、属性の個々の値の平均二乗偏差に等しくなります。 でグループ内の算術平均 (グループ平均) から算出され、各グループの単純分散または加重分散として計算されます。 ![]() または
または ![]() ,
,
ここで、 はグループ内のユニットの数です。
各グループのグループ内分散に基づいて、次のことを決定できます。 グループ内分散の全体平均:
.
3 つの分散間の関係は次のように呼ばれます。 差異を追加するためのルールこれによると、合計分散はグループ間の分散とグループ内分散の平均の合計に等しくなります。
例。 労働者の料金区分(資格)が労働生産性の水準に与える影響を調査したところ、以下のようなデータが得られました。
表 5 – 平均時間当たり生産量ごとの労働者の分布。
№ ピー/ピー |
第4類の労働者 |
第5類労働者 |
|||||
出力 |
出力 |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
この例では、従業員は要素の特性に従って 2 つのグループに分けられます。 バツ– ランクによって特徴付けられる資格。 結果として得られる形質、つまり生産量は、その影響 (グループ間変動) と他のランダムな要因 (グループ内変動) の両方によって変動します。 目標は、合計、グループ間、グループ内の 3 つの分散を使用してこれらの変動を測定することです。 で経験的決定係数は、結果として得られる特性の変動の割合を示します。 バツ因子記号の影響下で で。 残りの総変動量
他の要因の変化によって引き起こされます。 ![]() この例では、経験的な決定係数は次のようになります。
この例では、経験的な決定係数は次のようになります。
または66.7%、
これは、労働者の生産性の変動の 66.7% が資格の違いによるもので、33.3% が他の要因の影響によるものであることを意味します。経験的な相関関係
は、グループ化とパフォーマンス特性の間の密接な関係を示しています。 経験的決定係数の平方根として計算されます。
経験的な相関比は、 のような、0 から 1 までの値を取ることができます。
接続がない場合は =0 です。 この場合 =0、つまりグループ平均は互いに等しく、グループ間の変動はありません。 これは、グループ化特性要因が一般的な変動の形成に影響を与えないことを意味します。
接続が機能している場合は、=1 になります。 この場合、グループ平均の分散は合計分散 () に等しくなります。つまり、グループ内変動はありません。 これは、グループ化特性が研究対象の結果として得られる特性の変動を完全に決定することを意味します。
相関比の値が 1 に近づくほど、特性間のつながりが関数依存に近づきます。
例では ![]() 、これは労働者の生産性と資格の間に密接な関係があることを示しています。
、これは労働者の生産性と資格の間に密接な関係があることを示しています。
A – 条件付き平均(バリエーションシリーズの他の平均よりも頻繁に繰り返されます)
a – 条件付き平均からの条件付き偏差(ランク)
i – 間隔
ステージ 1 - グループの中央を決定します。
ステージ 2 – グループのランキング: バリアントの発生頻度が最も高いグループに 0 が割り当てられます。 それらの。 この場合は 7-11 (頻度 -32)。 特定のグループから上位にランク付けするには、(-1) を加算します。 下 - 増加 (+1)。
ステージ 3 – 条件付きモード (条件付き平均) の決定。 A はモーダル区間の中央です。 この場合、モーダル区間は 7 -11 であるため、A = 9 となります。
ステージ 4 – 間隔を決定します。 系列のすべてのグループの間隔は同じで、5 に等しくなります。i = 5/
ステージ 5 – 観察の総数の決定。 n = ∑p = 103。
取得したデータを式に代入します。
独立した仕事のためのタスク
グループ化された変動系列のデータを使用して、モーメント法を使用して算術平均を計算します。
オプション1
オプション No.2
オプション #3
オプション No.4
オプション #5
オプション #6
オプション No.7
オプション No.8
オプション No.9
オプションNo.10
オプション No.11
オプションNo.12
タスク No. 4 奇数のオプションを持つグループ化されていない変動系列の最頻値と中央値を決定する
病気の子供の入院治療期間(日数):15、14、18、17、16、20、19、16、14、16、17、12、18、19、20。
バリエーション シリーズのモードを決定するために、シリーズをランク付けする必要はありません。 ただし、中央値を決定する前に、変動系列を昇順または降順に並べる必要があります。
12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20.
モード = 16。 オプション 16 が最も多く出現します (3 回)。
発生頻度が最も高いバリアントが複数ある場合は、一連のバリエーションで 2 つ以上のモードが示される場合があります。
奇数の系列の中央値は、次の式で求められます。 
8 はランク付けされた変動シリーズの中央値のシリアル番号です。
それ。 私=17歳。
タスク No. 5 偶数のオプションを使用して、グループ化されていない変動系列の最頻値と中央値を決定します。
タスクで指定されたデータに基づいて、最頻値と中央値を見つける必要があります。
病気の子供の入院治療期間(日数): 15、14、18、17、16、20、19、16、14、16、17、12、18、19、20、11
ランク付けされたバリエーション シリーズを構築します。
11, 12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20
2 つの中央値 16 と 17 があります。この場合、中央値はそれらの算術平均として求められます。 私 = 16.5。
M av - モーメント法を使用して計算 = 61.6 kg
算術平均には 3 つの特性があります。
1. 平均は変動系列の中間の位置を占めます 。 厳密に対称な行: M=M0=Me.
2. 平均値は一般化された値であり、個々のデータのランダムな変動や差異は平均値の背後には見えず、母集団全体の典型的な値が明らかになります。 . 平均値は、個々の要因のランダムな影響を排除し、共通の特徴や既存のパターンを特定し、グループ全体の最も一般的で特徴的な特徴を完全かつ深く理解するために必要な場合に使用されます。
3. すべてのオプションの平均からの偏差の合計はゼロです : S(V-M)= 0 . これは、平均値が一部のバリアントのサイズより大きく、他のバリアントのサイズより小さいために発生します。
言い換えれば、真の偏差は真の平均からの変化です。 (d=v-M)は正または負の値になるため、合計は S すべての「+」d と「-」d はゼロに等しい。
平均のこの特性は、計算の正確さをチェックするために使用されます。 M.平均からのバリアントの偏差の合計がゼロの場合、平均は正しく計算されたと結論付けることができます。 決定するためのモーメント法 M.結局のところ、条件付き平均の場合、 あ true と等価になります Mさんその場合、条件付き平均からのバリアントの偏差の合計はゼロになります。
生物学における平均値の役割は非常に大きいです。 一方で、それらは現象全体を特徴付けるために使用され、他方では、個々の量を評価するために必要です。 個々の値を平均と比較することで、それぞれの貴重な特性が得られます。 平均値を使用するには、母集団の均一性の原則を厳密に遵守する必要があります。 この原則に違反すると、実際のプロセスの概念が歪められます。
社会経済的に異質な母集団から平均値を計算すると、その平均値は架空のものとなり、歪んでしまいます。 したがって、平均を正しく使用するには、平均が均一な統計的母集団を特徴づけていることを確認する必要があります。
における形質多様性の特徴
統計の概要
特定の特性の値は、相対的に均一であるにもかかわらず、母集団のすべてのメンバーで同じではありません。 たとえば、年齢、性別、居住地が同質の子どものグループでは、各子どもの身長は他の子どもの成長とは異なります。 同じことが、個人がクリニックを訪れる回数、各リウマチ患者の血中タンパク質のレベル、高血圧の患者の血圧レベルなどについても言えます。これは、症状の多様性と変動性を示しています。研究対象の集団。 変動性は、青少年のグループにおける成長の例によって実証的に説明できます。
統計により、特定のグループにおける各特性の多様性のレベルを決定する特別な基準によってこれを特徴付けることが可能になります。 そのような基準としては、 限界 (lim)、直列振幅 (午前)、標準偏差 (s) と変動係数 (C v)。これらの基準にはそれぞれ独立した意味があるため、個別に検討する必要があります。
限界- バリエーション系列のバリエーションは極値によって決定されます
振幅 (午前) - 極端なオプション間の違い
限界と振幅 - 各グループの成長の多様性の程度に関する特定の情報を提供します。 ただし、系列の制限と振幅の両方に 1 つの重大な欠点があります。それらは極端な変異の多様性のみを考慮しており、その内部構造を考慮した集合体における形質の多様性に関する情報を得ることができません。 実際のところ、多様性は極端なバリエーションではなく、グループの内部構造全体の分析に現れます。 したがって、これらの基準は、特に少数の観測値 (n<30).
集合体における形質の多様性の最も完全な説明は、いわゆる 標準偏差、ギリシャ文字「シグマ」で表される -s.
標準偏差を計算するには 2 つの方法があります: 算術平均とモーメント法.
算術平均の計算方法では、次の式が使用されます。 d-真の平均からの真の偏差オプション (V-M)。
この式は少数の観測値 (n<30), когда в вариационном ряду все частоты p= 1.
で R> 1 次のような式を使用します。
コンピューター技術が利用可能であれば、この公式は多くの観測にも使用されます。
この公式は、モーメント法を使用して「シグマ」を決定することを目的としています。
どこ:ああ、条件付き平均からの条件付き偏差 ( V-A); p-変異の発生頻度。 n-数値オプション; 私-グループ間の間隔のサイズ。
この方法は、コンピューター技術がなく、観測値の数が多いことと、複数桁の数値で表現される変異の両方により変異系列が扱いにくい場合に使用されます。 観測数が30以下の場合、2次時点 Pに置き換えられました (P-1).
標準偏差の式(4)から分かるように、分母には( P-1)、つまり 観測値の数が 30 (n £ 30) 以下の場合、( P-1)。 算術平均を求める場合 M系列のすべての要素を考慮して計算します。 あ、すべてのケースを考慮する必要はありませんが、1 つ少ないケースを考慮する必要があります (p-1)。
観測値の数が多い場合 (n>30)、式の分母が取得されます。 P、それで 単位は計算結果に影響を与えないため、自動的に省略されます。
標準偏差は名前付きの値であることに注意してください。したがって、バリアントと算術平均値に共通の指定が必要です (寸法 - kg、km などを参照)。
モーメント法による標準偏差の計算は、平均値を計算した後に行われます。
全体としての属性値の多様性のレベルを特徴付ける別の基準があります - 変動係数.
変動係数(Cv)- 標準偏差のパーセンテージとして計算されるため、多様性の相対的な尺度です。 (a) に算術平均 (M)。変動係数の式は次のとおりです。
形質の多様性の程度をおおよそ評価するには、次の変動係数の段階が使用されます。 係数が 20% を超える場合、強い多様性が認められます。 20〜10% - 平均であり、係数が 10% 未満の場合、多様性は弱いと見なされます。
変動係数は、フィーチャのサイズに差がある、または寸法が不均一であるフィーチャの多様性の程度を比較するときに使用されます。 新生児と 5 歳児の体重の多様性の程度を比較する必要があるとします。 新生児は 7 歳児よりも体重が軽いため、常にシグマが小さいことは明らかです。 属性自体の値が小さいほど、標準偏差は小さくなります。 この場合、多様性の程度の違いを判断するには、標準偏差ではなく、多様性の相対的な尺度である変動係数 Cv に焦点を当てる必要があります。
変動係数は、異なる次元を持ついくつかの形質の多様性の程度を評価および比較する場合にも非常に重要です。 標準偏差によって、これらの特性の多様性の程度の違いを判断することは依然として不可能です。 これを行うには、変動係数 - Cv を使用する必要があります。
標準偏差は、特性の分布系列の構造に関連付けられています。 これは次のように概略的に表すことができます。
統計理論により、正規分布では、すべてのケースの 68% が M±s 以内にあり、すべてのケースの 95.5% が M±2 以内にあり、母集団を構成するすべてのケースの 99.7% が M±3 以内にあることが証明されています。 。 このように、М±3s はバリエーション シリーズのほぼすべてをカバーしています。
系列の構造の規則性に関する統計のこの理論的立場は、標準偏差の実際の応用にとって非常に重要です。 このルールを使用すると、平均値の典型性の問題を明確にすることができます。 すべてのバリアントの 95% が M±2 秒以内にある場合、平均値は特定の系列の典型的な値となるため、集計内の観測値の数を増やす必要はありません。平均の典型性を判断するには、シグマ偏差を計算して実際の分布を理論上の分布と比較します。
標準偏差の実際的な重要性は、次のことを知ることでもあります。 Mそして s、実務に必要なバリエーションシリーズを構築できます。 シグマ ( s)は、例えば都市部と農村部の子どもの成長の変動(変動性)を比較する場合など、均一な特性の多様性の程度を比較するためにも使用されます。 シグマを知る ( s)、異なる測定単位 (センチメートル、キログラムなど) で表される特性の多様性の程度を比較するために必要な変動係数 (Cv) を計算できます。 これにより、全体としてより安定した (一定の) 兆候とそれほど安定していない兆候を識別することができます。
変動係数の比較 (履歴書)、一連の機能の中で何が最も安定した機能であるかについて結論を引き出すことができます。 標準偏差 (s) 1 つのオブジェクトの個々の特性を評価するためにも使用されます。 標準偏差は、シグマの数を示します ( s) 平均より (男)個々の測定値は拒否されます。
標準偏差 ( s)生物学と生態学で正常と病理学の問題を開発するときに使用できます。
最後に、標準偏差は式の重要な要素です。 tm- 算術平均の平均誤差 (代表性誤差):
どこ tm- 算術平均の平均誤差 (代表性の誤り)、 P- 観測値の数。
代表性。代表性の最も重要な理論的基礎は、上のサンプルと母集団に関するセクションで強調しました。 代表性とは、一般集団を構成する観察単位の特性(性別、年齢、職業、勤続年数など)を考慮したすべてのサンプルにおける代表性を意味します。 一般集団に対するサンプル集団のこの代表性は、以下に概説する特別な選択方法を使用して達成されます。
研究結果の信頼性の評価は、代表性の理論的基礎に基づいています。
研究結果の信頼性の評価
統計指標の信頼性は、統計指標が表す現実にどの程度対応しているかとして理解されるべきです。 信頼できる結果とは、歪めず、客観的な現実を正しく反映した結果です。
研究結果の信頼性を評価することは、サンプル母集団から得られた結果を母集団全体にどの程度の確率で適用できるかを判断することを意味します。
ほとんどの研究では、研究者は原則として、研究対象の現象の一部を扱い、そのような研究の結果から得られた結論を現象全体、つまり一般の人々に伝えなければなりません。
このように、現象の一部から現象の全体像やそのパターンを判断するためには、信頼性の評価が必要となる。
研究結果の信頼性を評価するには、次のことを判断する必要があります。
1) 代表性の誤差(算術平均と相対値の平均誤差) -T;
2) 平均値 (または相対値) の信頼限界。
3) 平均値(または相対値)の差の信頼性
(基準によるとt
);
4) 基準に従った比較されたグループ間の差異の信頼性c2 .
1. 平均 (または相対) 値の平均誤差 (代表性の誤差) の決定 - 例:
代表性エラー ( メートル)は、研究結果の信頼性を評価するために必要な最も重要な統計量です。 このエラーは、現象全体を部分的に特徴付ける必要がある場合に発生します。 これらの間違いは避けられません。 それらはサンプリング調査の性質に由来します。 母集団は、代表性誤差によって測定されるある程度の誤差を除いてサンプルから特徴付けることができます。
代表性誤差を、方法論、測定精度、算術などの通常の誤差の概念と混同することはできません。
代表性誤差の大きさによって、サンプルの観察中に得られた結果が、例外なく一般集団のすべての要素の継続的な研究中に得られる結果とどの程度異なるかが決まります。
これは、統計的手法で考慮される唯一のタイプの誤差であり、継続的な研究に移行しない限り排除することはできません。 代表性誤差はかなり小さな値、つまり許容誤差値まで減らすことができます。 これは、標本に十分な数の観測値を含めることによって行われます。 (P)。
それぞれの平均値は、 M(平均治療期間、平均身長、平均体重、平均血中タンパク質濃度など)および各相対値 - R(死亡率、罹患率など) は平均誤差を含めて提示する必要があります - T.したがって、サンプル母集団の算術平均は、 (男)には代表性誤差があり、これは算術平均の平均誤差 (mm) と呼ばれ、次の式で求められます。
この式からわかるように、算術平均の平均誤差の値は形質の多様性の程度に正比例し、観察数の平方根に反比例します。 その結果、多様性の程度を決定する際のこの誤差の大きさが減少します ( s)は観測数を増やすことで可能になります。
標本研究に十分な観察数を決定する方法は、この原則に基づいています。
相対値 (R)、サンプル研究から得られた値には、それぞれの代表性誤差もあります。これは平均相対誤差と呼ばれ、次のように表されます。 氏
平均相対誤差を求めるには (R)次の式が使用されます。
どこ R- 相対値。 指標がパーセンテージで表される場合、 q=100-P、もし R- ppmでは、 q=1000-P、もし R-小数で表すと、 q= 10000-R等。; P- 観測値の数。 観測値の数が 30 未満の場合、分母は ( P - 1 ).
サンプルから得られた各算術平均値または相対値には、独自の平均誤差を含める必要があります。 これにより、平均値と相対値の信頼限界を計算したり、比較した指標(調査結果)間の差異の信頼性を判断したりすることができます。
算術平均には、その本質をより完全に明らかにし、計算を簡素化するいくつかの特性があります。
1. 平均と頻度の合計との積は、常に、頻度とバリアントの積の合計と等しくなります。
2. さまざまな量の合計の算術平均は、これらの量の算術平均の合計に等しくなります。
3. 平均からの特性の個々の値の偏差の代数的合計はゼロです。
![]()
4. 平均からのオプションの偏差の 2 乗の合計は、他の任意の値からの偏差の 2 乗の合計よりも小さくなります。つまり、次のとおりです。
5. 一連のオプションすべてが同じ数値だけ減少または増加すると、平均は同じ数値だけ減少します。

6. 行内のすべてのオプションがある係数で増減すると、平均オプションもある係数で増減します。

7. すべての周波数 (重み) が係数によって増減しても、算術平均は変わりません。

この方法は、算術平均の数学的特性の使用に基づいています。 この場合、平均値は次の式を使用して計算されます。ここで、i は等間隔の値、または 0 に等しくない定数です。 m 1 – 一次モーメント。次の式で計算されます。  ; A は任意の定数です。
; A は任意の定数です。
18 高調波平均 シンプルかつ重み付け.
調和平均周波数 (f i) は不明だが、調査対象の特性のボリュームは既知である (x i *f i =M i) 場合に使用されます。
例 2 を使用して、2001 年の平均給与を決定します。
元の情報では2001年。 従業員数に関するデータはありませんが、平均給与に対する賃金基金の比率として簡単に計算できます。
それから  2769.4ルーブル、つまり 2001年の平均給与 -2769.4こする。
2769.4ルーブル、つまり 2001年の平均給与 -2769.4こする。
この場合、調和平均が使用されます。
ここで、M i は別の作業場における賃金基金です。 x i – 別のワークショップでの給与。
したがって、因子の 1 つが不明でも積「M」がわかっている場合は、調和平均が使用されます。
調和平均は、平均労働生産性、基準達成率の平均、平均給与などの計算に使用されます。
積「M」が互いに等しい場合、平均調和素数が使用されます。ここで、n はオプションの数です。
平均的な幾何学的および平均的な年代。
幾何平均は現象のダイナミクスを分析するために使用され、平均成長係数を決定することができます。 幾何平均を計算する場合、特性の個々の値は通常、系列の各レベルと前のレベルの比率としてチェーン値の形式で構築されたダイナミクスの相対的な指標を表します。
![]() 、 - チェーンの成長係数。
、 - チェーンの成長係数。
n – チェーン成長係数の数。
ソース データが特定の日付の時点で指定されている場合、特性の平均レベルは平均時系列公式を使用して決定されます。 日付 (瞬間) 間の間隔が等しい場合、平均レベルは単純な時系列平均の公式によって決定されます。
具体的な例を用いて計算を見てみましょう。
例。 以下のデータは、1997 年上半期 (月初め) のロシアの銀行の家計預金残高に関するものです。
1997 年上半期の家計預金の平均残高(平均時系列単純計算式による)は次のとおりです。

