Opis: War Thunder je vojaška MMO igra naslednje generacije, posvečena...

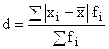
Določimo povprečne vrednosti:
Način (Mo) \u003d 11, ker ta varianta se najpogosteje pojavlja v variacijskih serijah (p=6).
Mediana (Me) - serijska številka možnosti, ki zasedajo srednji položaj = 23, to mesto v seriji variacij zaseda možnost, ki je enaka 11. Aritmetična sredina (M) vam omogoča najbolj popolno karakterizacijo povprečna raven preučevana lastnost. Za izračun aritmetične sredine uporabljamo dve metodi: metodo aritmetične sredine in metodo momentov.
Če je pogostost pojavljanja vsake različice v nizu variacij enaka 1, se enostavna aritmetična sredina izračuna z uporabo metode aritmetične sredine: M = .
Če je pogostost pojavljanja različice v variacijskem nizu drugačna od 1, se utežena aritmetična sredina izračuna z uporabo metode aritmetične sredine:
Po metodi trenutkov: A - pogojno povprečje,
M = A + =11 += 10,4 d=V-A, A=Mo=11
Če je število možnosti v variacijski seriji več kot 30, se zgradi združena serija. Gradnja združene serije:
1) določitev Vmin in Vmax Vmin=3, Vmax=20;
2) določitev števila skupin (po tabeli);
3) izračun intervala med skupinami jaz = 3;
4) določitev začetka in konca skupin;
5) določitev frekvenčne različice vsake skupine (tabela 2).
tabela 2
Tehnika izdelave združene serije
|
Trajanje zdravljenje v dneh |
|||||||
|
n=45 p=480 p=30 2 p=766 |
Prednost združenega variacijskega niza je v tem, da raziskovalec ne dela z vsako različico, temveč samo z različicami, ki so povprečne za vsako skupino. Tako je veliko lažje izračunati povprečje.
Vrednost te ali one lastnosti ni enaka za vse člane populacije, kljub njeni relativni homogenosti. Za to značilnost statistične populacije je značilna ena od skupinskih lastnosti splošne populacije - raznolikost lastnosti. Na primer, vzemimo skupino 12-letnih dečkov in izmerimo njihovo višino. Po izračunih bo povprečna raven te lastnosti 153 cm, vendar povprečje označuje splošno merilo preučevane lastnosti. Med fanti te starosti so fantje, visoki 165 cm ali 141 cm, več kot je fantov, ki imajo drugo višino od 153 cm, večja je pestrost te lastnosti v statistični populaciji.
Statistika nam omogoča, da označimo to lastnost po naslednjih merilih:
omejitev (lim),
amplituda (Amp),
standardni odklon ( y) ,
koeficient variacije (Cv).
Omejitev (lim) je določen z ekstremnimi vrednostmi variante v variacijskem nizu:
lim=Vmin /Vmaks
Amplituda (Amp) - razlika ekstremnih možnosti:
Amp=Vmax -Vmin
Te vrednosti upoštevajo le raznolikost skrajnih možnosti in ne omogočajo pridobivanja informacij o raznolikosti lastnosti v agregatu ob upoštevanju njegove notranje strukture. Zato se ta merila lahko uporabijo za približno karakterizacijo raznolikosti, zlasti z majhnim številom opazovanj (n<30).
variacijske vrste medicinske statistike
Razpon variacije (ali obseg variacije) - je razlika med največjo in najmanjšo vrednostjo lastnosti:
V našem primeru je razpon variacije izmenske proizvodnje delavcev: v prvi brigadi R=105-95=10 otrok, v drugi brigadi R=125-75=50 otrok. (5-krat več). To nakazuje, da je proizvodnja 1. brigade bolj "stabilna", vendar ima druga brigada več rezerv za rast proizvodnje, ker. če vsi delavci dosežejo največjo produktivnost za to brigado, lahko proizvede 3 * 125 = 375 delov, v 1. brigadi pa le 105 * 3 = 315 delov.
Če skrajne vrednosti atributa niso značilne za populacijo, se uporabijo razponi kvartila ali decila. Kvartilni razpon RQ= Q3-Q1 pokriva 50 % populacije, prvi decilni razpon RD1 = D9-D1 pokriva 80 % podatkov, drugi decilni razpon RD2= D8-D2 pokriva 60 %.
Pomanjkljivost indikatorja variacijskega obsega je, da njegova vrednost ne odraža vseh nihanj lastnosti.
Najenostavnejši generalizacijski indikator, ki odraža vsa nihanja lastnosti, je srednji linearni odklon, ki je aritmetična sredina absolutnih odstopanj posameznih opcij od njihove povprečne vrednosti:
,
za združene podatke ![]() ,
,
kjer je хi vrednost atributa v diskretni seriji ali sredina intervala v intervalni porazdelitvi.
V zgornjih formulah so razlike v števcu vzete modulo, sicer bo glede na lastnost aritmetične sredine števec vedno enak nič. Zato se povprečno linearno odstopanje v statistični praksi redko uporablja, le v primerih, ko je seštevanje kazalnikov brez upoštevanja predznaka ekonomsko smiselno. Z njegovo pomočjo se na primer analizira sestava zaposlenih, donosnost proizvodnje, zunanjetrgovinski promet.
Varianca značilnosti je povprečni kvadrat odstopanj variante od njihove povprečne vrednosti:
enostavna varianta ![]() ,
,
utežena varianca  .
.
Formulo za izračun variance je mogoče poenostaviti:
Tako je varianca enaka razliki med povprečjem kvadratov variante in kvadratom povprečja različice populacije:  .
.
Zaradi seštevka kvadratov odstopanj pa varianca daje popačeno predstavo o odstopanjih, zato se iz nje izračuna povprečje. standardni odklon, ki kaže, koliko posamezne variante atributa v povprečju odstopajo od svoje povprečne vrednosti. Izračunano s kvadratnim korenom variance:
za nezdružene podatke  ,
,
za variacijsko serijo 
Manjša ko je vrednost variance in standardnega odklona, bolj homogena je populacija, bolj zanesljiva (tipična) bo povprečna vrednost.
Srednji linearni in srednji kvadratni odklon sta poimenovani števili, tj. izraženi sta v merskih enotah lastnosti, sta po vsebini enaki in po vrednosti blizu.
Priporočljivo je izračunati absolutne kazalnike variacije s pomočjo tabel.
Tabela 3 - Izračun značilnosti variacije (na primeru obdobja podatkov o izmenskem izidu delovnih skupin)
Število delavcev |
Sredina intervala |
Ocenjene vrednosti |
|||||
Skupaj: |
|||||||
Povprečna izmena dela delavcev: ![]()
Povprečno linearno odstopanje: ![]()
Izhodna disperzija: 
Standardni odklon proizvodnje posameznih delavcev od povprečne proizvodnje:
.
Izračun varianc je povezan z okornimi izračuni (še posebej, če je povprečje izraženo kot veliko število z več decimalnimi mesti). Izračune je mogoče poenostaviti z uporabo poenostavljene formule in disperzijskih lastnosti.
Disperzija ima naslednje lastnosti:
 ,
,
 , potem oz
, potem oz 
Z uporabo lastnosti variance in najprej zmanjševanjem vseh variant populacije za vrednost A, nato delitvijo z vrednostjo intervala h, dobimo formulo za izračun variance v variacijskih serijah z enakimi intervali način trenutkov: ,
,
kjer je disperzija, izračunana z metodo momentov;
h je vrednost intervala variacijske serije;
– nove (preoblikovane) variantne vrednosti;
A je konstantna vrednost, ki se uporablja kot sredina intervala z najvišjo frekvenco; ali različica z najvišjo frekvenco; 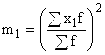 je kvadrat momenta prvega reda;
je kvadrat momenta prvega reda;
je moment drugega reda.
Izračunajmo varianco po metodi momentov na podlagi podatkov o izmenskem učinku delovne ekipe.
Tabela 4 - Izračun disperzije po metodi momentov
Skupine proizvodnih delavcev, kos. |
Število delavcev |
Sredina intervala |
Ocenjene vrednosti |
||
Postopek izračuna:


Med znaki, ki jih proučuje statistika, so takšni, ki imajo samo dva medsebojno izključujoča se pomena. To so alternativni znaki. Podani sta jim dve kvantitativni vrednosti: možnost 1 in 0. Pogostost možnosti 1, ki je označena s p, je delež enot, ki imajo to lastnost. Razlika 1-p=q je frekvenca možnosti 0. Tako
xi |
|
Aritmetična sredina alternativne značilnosti ![]() , ker je p+q=1.
, ker je p+q=1.
Varianca značilnosti
, Ker 1-p=q
Tako je varianca alternativnega atributa enaka zmnožku deleža enot, ki imajo ta atribut, in deleža enot, ki tega atributa nimajo.
Če sta vrednosti 1 in 0 enako pogosti, to je p=q, doseže varianca svoj maksimum pq=0,25.
Spremenljivka variance se uporablja v vzorčnih raziskavah, na primer kakovost izdelka.
Disperzija je za razliko od drugih značilnosti variacije aditivna količina. Se pravi v agregatu, ki je razdeljen na skupine po faktorskem kriteriju X , rezultantna varianca l lahko razčlenimo na varianco znotraj posamezne skupine (znotraj skupine) in varianco med skupinami (med skupinami). Potem, skupaj s preučevanjem variacije lastnosti v populaciji kot celoti, postane mogoče preučevati variacije v vsaki skupini, pa tudi med temi skupinami.
Skupna varianca meri variacijo lastnosti pri nad celotno populacijo pod vplivom vseh dejavnikov, ki so povzročili to variacijo (odklone). Je enak srednjemu kvadratu odstopanj posameznih vrednosti lastnosti pri celotnega povprečja in se lahko izračuna kot enostavna ali utežena varianca.
Medskupinska varianca označuje variacijo efektivne lastnosti pri, ki jih povzroča vpliv znaka-faktorja X ki je osnova skupine. Označuje variacijo skupinskih povprečij in je enaka srednjemu kvadratu odstopanj skupinskih povprečij od celotnega povprečja:  ,
,
kjer je aritmetična sredina i-te skupine;
– število enot v i-ti skupini (pogostnost i-te skupine);
je skupno povprečje populacije.
Varianca znotraj skupine odraža naključno variacijo, tj. tisti del variacije, ki je posledica vpliva neupoštevanih dejavnikov in ni odvisen od dejavnika atributa, na katerem temelji razvrščanje. Označuje variacijo posameznih vrednosti glede na skupinska povprečja, enaka je srednjemu kvadratu odstopanj posameznih vrednosti lastnosti pri znotraj skupine iz aritmetične sredine te skupine (skupinske sredine) in se izračuna kot enostavna ali tehtana varianca za vsako skupino: ![]() oz
oz ![]() ,
,
kjer je število enot v skupini.
Na podlagi znotrajskupinskih varianc za vsako skupino je mogoče določiti skupno povprečje varianc znotraj skupine:
.
Razmerje med tremi variancami se imenuje pravila dodajanja variance, po katerem je skupna varianca enaka vsoti medskupinske variance in povprečja znotrajskupinskih varianc:
Primer. Pri preučevanju vpliva tarifne kategorije (kvalifikacije) delavcev na stopnjo produktivnosti njihovega dela so bili pridobljeni naslednji podatki.
Tabela 5 - Porazdelitev delavcev po povprečni urni proizvodnji.
№ p/p |
Delavci 4. kategorije |
Delavci 5. kategorije |
|||||
Telovaditi |
Telovaditi |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
V tem primeru so delavci razdeljeni v dve skupini glede na faktor X- kvalifikacije, za katere je značilen njihov rang. Učinkovita lastnost - proizvodnja - se spreminja tako pod njenim vplivom (medskupinska variacija) kot tudi zaradi drugih naključnih dejavnikov (znotrajskupinska variacija). Izziv je izmeriti te variacije s tremi variancami: skupno, med skupinami in znotraj skupine. Empirični koeficient determinacije kaže delež variacije dobljene lastnosti pri pod vplivom faktorskega znaka X. Ostalo popolna variacija pri posledica sprememb drugih dejavnikov.
V primeru je empirični koeficient determinacije: ![]() ali 66,7 %.
ali 66,7 %.
To pomeni, da je 66,7 % variacije v produktivnosti dela delavcev posledica razlik v kvalifikacijah, 33,3 % pa je posledica vpliva drugih dejavnikov.
Empirična korelacijska relacija kaže na tesnost razmerja med združevanjem in učinkovitimi značilnostmi. Izračuna se kot kvadratni koren empiričnega koeficienta determinacije:
Empirično korelacijsko razmerje , kot tudi , lahko sprejmejo vrednosti od 0 do 1.
Če povezave ni, potem =0. V tem primeru je =0, kar pomeni, da so povprečja skupine med seboj enaka in ni variacije med skupinami. To pomeni, da skupinski znak - dejavnik ne vpliva na oblikovanje splošne variacije.
Če je razmerje funkcionalno, potem =1. V tem primeru je varianca skupinskih povprečij enaka skupni varianci (), kar pomeni, da ni variacije znotraj skupine. To pomeni, da značilnost združevanja v celoti določa variacijo nastale lastnosti, ki jo preučujemo.
Bližje ko je vrednost korelacijskega razmerja ena, bližje, bližje funkcionalni odvisnosti je razmerje med značilnostmi.
Za kvalitativno oceno tesnosti povezave med znaki se uporabljajo razmerja Chaddock.
V primeru ![]() , kar kaže na tesno povezavo med produktivnostjo delavcev in njihovimi kvalifikacijami.
, kar kaže na tesno povezavo med produktivnostjo delavcev in njihovimi kvalifikacijami.
A - pogojno povprečje (pogosteje kot drugi, ki se ponavljajo v variacijski seriji)
a - pogojno odstopanje od pogojnega povprečja (rang)
i - interval
1. stopnja - določitev sredine skupin;
2. stopnja - razvrstitev skupin: 0 se pripiše skupini, v kateri je pogostnost pojavljanja različice največja. Tisti. v tem primeru 7-11 (frekvenca -32). Navzgor od te skupine se razvrstitev izvede s seštevanjem (-1). Dol - povečaj (+1).
3. stopnja - določitev pogojnega načina (pogojno povprečje). A je sredina modalnega intervala. V našem primeru je modalni interval 7 -11, torej A = 9.
4. stopnja - določitev intervala. Interval v vseh skupinah serije je enak in enak 5. i = 5/
5. stopnja - določitev skupnega števila opazovanj. n = ∑p = 103.
Dobljene podatke nadomestimo s formulo:
Naloge za samostojno delo
S pomočjo podatkov združenega variacijskega niza izračunajte aritmetično sredino po metodi momentov.
Možnost številka 1
Možnost številka 2
Možnost številka 3
Možnost številka 4
Možnost številka 5
Možnost številka 6
Možnost številka 7
Možnost številka 8
Možnost številka 9
Možnost številka 10
Možnost številka 11
Možnost številka 12
Naloga №4 Določanje načina in mediane v nezdruženem variacijskem nizu z lihim številom možnosti
Termini bolnišničnega zdravljenja bolnih otrok v dnevih: 15, 14, 18, 17, 16, 20, 19, 16, 14, 16, 17, 12, 18, 19, 20.
Za določitev načina v variacijski seriji je razvrstitev serije neobvezna. Vendar pa je treba pred določitvijo mediane zgraditi niz variacij v naraščajočem ali padajočem vrstnem redu.
12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20.
Način = 16. možnost 16 se pojavi največkrat (3-krat).
Če obstaja več možnosti z najvišjo pogostostjo pojavljanja, se lahko v nizu različic navedeta dva ali več načinov.
Mediana v nizu z lihim številom je določena s formulo: 
8 je zaporedna številka mediane v rangirani variacijski seriji,
potem. Jaz = 17.
Naloga №5 Določanje načina in mediane v nezdruženi variacijski seriji s sodim številom možnosti.
Na podlagi podatkov, navedenih v nalogi, morate najti modus in mediano
Termini bolnišničnega zdravljenja bolnih otrok v dnevih: 15, 14, 18, 17, 16, 20, 19, 16, 14, 16, 17, 12, 18, 19, 20, 11
Gradimo razvrščeno variacijsko serijo:
11, 12, 14, 14, 15, 16, 16, 16, 17, 17, 18, 18, 19, 19, 20, 20
Imamo dve mediani števili 16 in 17. V tem primeru je mediana najdena kot aritmetična sredina med njima. Jaz = 16,5.
M cf - izračunano po metodi momentov = 61,6 kg
Aritmetična sredina ima tri lastnosti.
1. Srednji zavzema srednji položaj v variacijski seriji . V strogo simetrični vrsti: M \u003d M 0 \u003d M e.
2. Povprečje je posplošujoča vrednost in naključna nihanja, razlike v posameznih podatkih niso vidne za povprečjem, razkriva tisto tipično, ki je značilno za celotno populacijo. . Povprečje se uporablja, kadar je treba izključiti naključni vpliv posameznih dejavnikov, ugotoviti skupne značilnosti, obstoječe vzorce, dobiti popolno in globoko predstavo o najpogostejših in značilnih lastnostih celotne skupine.
3. Vsota odstopanj vseh možnosti od povprečja je nič : S(V-M)=0 . To je zato, ker povprečna vrednost presega dimenzije nekaterih različic in je manjša od dimenzij drugih različic.
Z drugimi besedami, resnično odstopanje variante od prave srednje vrednosti (d=v-m) lahko pozitiven ali negativen, torej vsota S vsi "+"d in "-"d so enaki nič.
Ta lastnost povprečja se uporablja pri preverjanju pravilnosti izračunov M.Če je vsota odstopanj variante od povprečja enaka nič, potem lahko sklepamo, da je povprečje izračunano pravilno. Ta lastnost temelji na metodi določanja trenutkov M. Konec koncev, če je pogojno povprečje AMPAK bo enako resnici M, potem bo vsota odstopanj variante od pogojne sredine enaka nič.
Vloga povprečij v biologiji je izjemno velika. Po eni strani se uporabljajo za karakterizacijo pojavov kot celote, po drugi strani pa so potrebni za vrednotenje posameznih količin. Pri primerjavi posameznih vrednosti s povprečji se za vsako od njih pridobijo dragocene značilnosti. Uporaba povprečij zahteva dosledno upoštevanje načela homogenosti populacije. Kršitev tega načela izkrivlja predstavo o resničnih procesih.
Izračun povprečij iz socialno-ekonomsko heterogene populacije jih dela fiktivne, izkrivljene. Zato je treba za pravilno uporabo povprečij zagotoviti, da označujejo homogene statistične populacije.
ZNAČILNOSTI RAZLIČNOSTI ZNAKA B
STATISTIČNA POPULACIJA
Vrednost te ali one lastnosti ni enaka za vse člane populacije, kljub njeni relativni homogenosti. Na primer, v skupini otrok, ki je homogena po starosti, spolu in kraju bivanja, se višina vsakega otroka razlikuje od višine njegovih vrstnikov. Enako lahko rečemo o številu obiskov posameznikov v ambulanti, o ravni beljakovin v krvi pri vsakem bolniku z revmo, o ravni krvnega tlaka pri osebah s hipertenzijo itd. To kaže na raznolikost, nihanje znak v proučevani populaciji. Variabilnost lahko kljubovalno predstavimo s primerom rasti v skupinah mladostnikov.
Statistika nam omogoča, da to označimo s posebnimi kriteriji, ki določajo stopnjo raznolikosti posamezne lastnosti v določeni skupini. Ta merila vključujejo meja (lim), amplituda serije (sem), standardni odklon (s) in koeficient variacije (C v). Ker ima vsako od teh meril svojo lastno neodvisno vrednost, se je treba na njih ustaviti ločeno.
Omejitev- določeno z ekstremnimi vrednostmi variante v variacijski seriji
Amplituda (sem) - razlika skrajnosti
Meja in amplituda - podajte nekaj informacij o stopnji raznolikosti rasti v vsaki skupini. Vendar imata tako meja kot amplituda serije eno pomembno pomanjkljivost. Upoštevajo le raznolikost ekstremnih variant in ne omogočajo pridobivanja informacij o raznolikosti lastnosti v agregatu ob upoštevanju njene notranje strukture. Dejstvo je, da se raznolikost ne kaže toliko v ekstremnih različicah kot v analizi celotne notranje strukture skupine. Zato se ta merila lahko uporabijo za približno karakterizacijo raznolikosti, zlasti z majhnim številom opazovanj (n<30).
Najbolj popoln opis raznovrstnosti lastnosti v agregatu daje ti standardni odklon, označen z grško črko "sigma" -s.
Obstajata dva načina za izračun standardnega odklona: aritmetična sredina in metoda momentov.
Pri metodi izračuna aritmetične sredine se uporablja formula, kjer d- pravo odstopanje variante od prave sredine (V-M).
Formula se uporablja z majhnim številom opazovanj (n<30), когда в вариационном ряду все частоты p= 1.
pri R> 1 uporabite formulo, kot je ta:
V prisotnosti računalniške tehnologije se ta formula uporablja tudi za veliko število opazovanj.
Ta formula je zasnovana za določanje "sigme" z metodo trenutkov:
kje:a- pogojno odstopanje od pogojnega povprečja ( V-A); p- pogostost pojavljanja za različice; n- možnost številke; jaz- velikost intervala med skupinami.
Ta metoda se uporablja v primerih, ko ni računalniške tehnologije, variacijski niz pa je okoren tako zaradi velikega števila opazovanj kot zaradi variantnosti, izražene v večvrednih številih. S številom opazovanj, enakim 30 ali manj, v trenutku druge stopnje p zamenjati za (P-1).
Kot je razvidno iz formule za standardni odklon (4), je imenovalec ( p-1), tj. kadar je število opazovanj enako ali manjše od 30 (n £ 30), je treba vzeti imenovalec formule ( p-ena). Če pri določanju aritmetične sredine M upoštevajte vse elemente serije, nato pa izračunajte a, treba jemati ne vse primere, ampak enega manj (p-1).
Pri velikem številu opazovanj (n>30) je imenovalec formule P, torej kot enota ne spremeni rezultatov izračuna in je zato samodejno izpuščena.
Upoštevati je treba, da je standardni odklon poimenovana vrednost, zato mora imeti skupno oznako za varianto in aritmetično sredino (dimenzija - kg, glej km itd.).
Izračun standardnega odklona po metodi trenutkov se izvede po izračunu povprečne vrednosti.
Obstaja še eno merilo, ki označuje stopnjo raznolikosti vrednosti lastnosti v agregatu, - koeficient variacije.
Koeficient variacije (Cv)- je relativno merilo raznolikosti, saj se izračuna kot odstotek standardnega odklona (a) za aritmetična sredina (M). Formula za koeficient variacije je:
Za približno oceno stopnje raznolikosti lastnosti se uporabljajo naslednje gradacije koeficienta variacije. Če je koeficient večji od 20 %, je opazna velika raznolikost; pri 20-10% - povprečje, in če je koeficient manjši od 10%, se šteje, da je raznolikost šibka.
Koeficient variacije se uporablja pri primerjavi stopnje raznolikosti značilnosti, ki imajo razlike v velikosti značilnosti ali njihove neenake dimenzije. Recimo, da želite primerjati stopnjo raznolikosti telesne teže pri novorojenčkih in 5-letnih otrocih. Jasno je, da bodo novorojenčki vedno imeli manj "sigme" kot sedemletni otroci, saj je njihova individualna teža manjša. Standardni odklon bo manjši tam, kjer je manjša vrednost same lastnosti. V tem primeru se za določitev razlike v stopnji raznolikosti ni treba osredotočiti na standardno deviacijo, temveč na relativno merilo raznolikosti - koeficient variacije Cv.
Koeficient variacije je zelo pomemben tudi za ocenjevanje in primerjavo stopnje raznolikosti več značilnosti z različnimi dimenzijami. S srednjim kvadratnim odstopanjem je še vedno nemogoče oceniti razliko v stopnji raznolikosti navedenih znakov. Če želite to narediti, morate uporabiti koeficient variacije - Cv.
Standardni odklon je povezan s strukturo serije porazdelitve značilnosti. Shematično je to mogoče predstaviti na naslednji način.
Teorija statistike je dokazala, da je pri normalni porazdelitvi 68 % vseh primerov znotraj M ± s, 95,5 % vseh primerov znotraj M ± 2 s in 99,7 % vseh primerov, ki sestavljajo populacijo, znotraj M ± 3 s. . Tako M±3s pokriva skoraj celotno variacijsko vrsto.
To teoretično stališče statistike o pravilnostih strukture vrste je zelo pomembno za praktično uporabo standardnega odklona. To pravilo lahko uporabite za razjasnitev - vprašanje tipičnosti povprečja. Če je 95% vseh variant znotraj M ± 2s, potem je povprečje - značilno za to serijo in ni treba povečati števila opazovanj v agregatu. Za določitev tipičnosti povprečja se dejanska porazdelitev primerja s teoretično z izračunom sigma odstopanj.
Praktični pomen standardne deviacije je tudi v tem, da vedenje M in s, je mogoče sestaviti potrebne variacijske serije za praktično uporabo. Sigma ( s) se uporabljajo tudi za primerjavo stopnje raznolikosti homogenih značilnosti, na primer pri primerjavi nihanj (variabilnosti) v rasti otrok v mestih in na podeželju. Poznavanje sigme ( s), je mogoče izračunati koeficient variacije (Cv), potreben za primerjavo stopnje raznolikosti lastnosti, izraženih v različnih merskih enotah (centimetri, kilogrami itd.). To vam omogoča, da prepoznate bolj stabilne (trajne) in manj stabilne znake v agregatu.
Primerjava koeficientov variacije (Cv), mogoče je sklepati o tem, katera je najbolj stabilna značilnost v celoti značilnosti. Standardni odklon (s) Uporablja se tudi za vrednotenje posameznih lastnosti enega predmeta. Standardni odklon označuje, koliko sigm ( s) od povprečja (M) posamezne meritve zavrnejo.
Standardni odklon ( s) se lahko uporablja v biologiji in ekologiji pri razvoju problemov norme in patologije.
Končno je standardni odklon pomemben sestavni del formule t m- povprečna napaka aritmetične sredine (napaka reprezentativnosti):
kje t m- povprečna napaka aritmetične sredine (napaka reprezentativnosti), p- število opazovanj.
Reprezentativnost. Najpomembnejše teoretične osnove reprezentativnosti so bile izpostavljene zgoraj v poglavju o vzorčenju in splošni populaciji. Reprezentativnost pomeni reprezentativnost v vzorčnem nizu vseh obravnavanih značilnosti (spol, starost, poklic, delovna doba itd.) enot opazovanja, ki sestavljajo generalno populacijo. To reprezentativnost vzorčne populacije glede na splošno populacijo dosežemo s posebnimi selekcijskimi metodami, ki so opisane v nadaljevanju.
Ocena zanesljivosti rezultatov raziskave temelji na teoretičnih osnovah reprezentativnosti.
OCENA ZANESLJIVOSTI REZULTATOV RAZISKOVANJA
Zanesljivost statističnih kazalnikov je treba razumeti kot stopnjo njihove skladnosti z realnostjo, ki jo odražajo. Zanesljivi rezultati so tisti, ki ne izkrivljajo in pravilno odražajo objektivno resničnost.
Oceniti zanesljivost rezultatov študije pomeni ugotoviti, s kakšno verjetnostjo je mogoče rezultate, pridobljene na vzorčni populaciji, prenesti na celotno populacijo.
V večini študij se mora raziskovalec praviloma ukvarjati z delom proučevanega pojava, zaključke na podlagi rezultatov takšne študije pa prenesti na celoten pojav – na splošno populacijo.
Ocena zanesljivosti je torej nujna, da lahko po delu pojava presojamo pojav kot celoto, njegove zakonitosti.
Ocena zanesljivosti rezultatov študije vključuje določitev:
1) napake reprezentativnosti (povprečne napake aritmetičnih sredin in relativnih vrednosti) - t;
2) meje zaupanja povprečnih (ali relativnih) vrednosti;
3) zanesljivost razlike med povprečnimi (ali relativnimi) vrednostmi
(glede na kriterijt
);
4) zanesljivost razlike med primerjanimi skupinami po kriterijuc 2 .
1. Določitev povprečne napake srednje (ali relativne) vrednosti (napaka reprezentativnosti) - t.j.
Reprezentativna napaka ( m) je najpomembnejša statistična vrednost, ki je potrebna za oceno zanesljivosti rezultatov študije. Ta napaka se pojavi v tistih primerih, ko je treba delno označiti pojav kot celoto. Te napake so neizogibne. Izhajajo iz narave vzorčenja; splošno populacijo lahko karakterizira vzorčna populacija le z določeno napako, merjeno z napako reprezentativnosti.
Napake reprezentativnosti ne smemo zamenjevati z običajno predstavo o napakah: metodoloških, merilne natančnosti, aritmetičnih itd.
Velikost napake reprezentativnosti določa, koliko se rezultati, dobljeni med selektivnim opazovanjem, razlikujejo od rezultatov, ki bi jih lahko dobili z neprekinjeno študijo vseh elementov splošne populacije brez izjeme.
To je edina vrsta napak, ki jih upoštevajo statistične metode, ki jih ni mogoče odpraviti, če ne preidemo na kontinuirano študijo. Napake reprezentativnosti lahko zmanjšamo na dokaj majhno vrednost, to je na vrednost dopustne napake. To se naredi tako, da se v vzorec vključi zadostno število opazovanj. (P).
Vsako povprečje je M(povprečno trajanje zdravljenja, povprečna višina, povprečna telesna teža, povprečna raven beljakovin v krvi itd.), kot tudi vsaka relativna vrednost - R(stopnja umrljivosti, obolevnosti itd.) je treba predstaviti s povprečno napako - t. Tako je aritmetična sredina vzorca (M) ima napako reprezentativnosti, ki jo imenujemo povprečna napaka aritmetične sredine (m m) in jo določimo po formuli:
Kot je razvidno iz te formule, je vrednost povprečne napake aritmetične sredine premo sorazmerna s stopnjo raznolikosti značilnosti in obratno sorazmerna s kvadratnim korenom števila opazovanj. Zato je zmanjšanje velikosti te napake pri določanju stopnje raznolikosti ( s) je mogoče s povečanjem števila opazovanj.
To načelo je osnova za metodo določanja zadostnega števila opazovanj za vzorčno študijo.
Relativne vrednosti (R), pridobljeni v vzorčni študiji imajo tudi svojo napako reprezentativnosti, ki jo imenujemo povprečna napaka relativne vrednosti in jo označimo m str
Za določitev povprečne napake relativne vrednosti (R) uporablja se naslednja formula:
kje R- relativna vrednost. Če je indikator izražen v odstotkih, potem q=100-P,če R- v ppm, torej q=1000-P,če R- v decimilih, torej q= 10000-R itd.; p- število opazovanj. Če je število opazovanj manjše od 30, je treba vzeti imenovalec ( P - 1 ).
Vsaka aritmetična sredina ali relativna vrednost, pridobljena iz vzorčne populacije, mora biti predstavljena z lastno srednjo napako. To omogoča izračun meja zaupanja povprečnih in relativnih vrednosti ter ugotavljanje zanesljivosti razlike med primerjanimi kazalci (rezultati raziskav).
Aritmetična sredina ima številne lastnosti, ki bolj razkrivajo njeno bistvo in poenostavljajo izračun:
1. Zmnožek povprečja in vsote frekvenc je vedno enak vsoti zmnožkov variant in frekvenc, tj.
2. Aritmetična sredina vsote spremenljivih vrednosti je enaka vsoti aritmetičnih sredin teh vrednosti:
3. Algebraična vsota odstopanj posameznih vrednosti atributa od povprečja je nič:
![]()
4. Vsota kvadratov odstopanj opcij od povprečja je manjša od vsote kvadratov odstopanj od katere koli druge poljubne vrednosti, tj.:
5. Če se vse različice serije zmanjšajo ali povečajo za enako število, se bo povprečje zmanjšalo za isto število:

6. Če se vse različice serije zmanjšajo ali povečajo za faktor, se bo tudi povprečje zmanjšalo ali povečalo za faktor:

7. Če vse frekvence (uteži) povečamo ali zmanjšamo za faktor, se aritmetična sredina ne spremeni:

Ta metoda temelji na uporabi matematičnih lastnosti aritmetične sredine. V tem primeru se povprečna vrednost izračuna po formuli: , kjer je i vrednost enakega intervala ali katerega koli konstantnega števila, ki ni enako 0; m 1 - trenutek prvega reda, ki se izračuna po formuli:  ; A je poljubno konstantno število.
; A je poljubno konstantno število.
18 ENOSTAVNO HARMONIČNO POVPREČNO IN OBTEŽENO.
Povprečna harmonika se uporablja v primerih, ko je pogostnost neznana (f i), obseg proučevane lastnosti pa je znan (x i *f i =M i).
S pomočjo primera 2 določimo povprečno plačo v letu 2001.
V prvotnih informacijah iz leta 2001. podatka o številu zaposlenih ni, ni pa ga težko izračunati kot razmerje med maso in povprečno plačo.
Potem  2769,4 rubljev, tj. povprečna plača v letu 2001 -2769,4 rubljev.
2769,4 rubljev, tj. povprečna plača v letu 2001 -2769,4 rubljev.
V tem primeru se uporablja harmonična sredina: ,
kjer je M i sklad plač v ločeni delavnici; x i - plača v ločeni trgovini.
Zato se harmonična sredina uporablja, kadar eden od faktorjev ni znan, vendar je produkt "M" znan.
Harmonična sredina se uporablja za izračun povprečne produktivnosti dela, povprečnega odstotka izpolnjevanja normativov, povprečne plače itd.
Če so produkti "M" med seboj enaki, se uporabi harmonična enostavna sredina: , kjer je n število možnosti.
GEOMETRIJSKO POVPREČJE IN KRONOLOŠKO POVPREČJE.
Geometrična sredina se uporablja za analizo dinamike pojavov in vam omogoča, da določite povprečno stopnjo rasti. Pri izračunu geometričnega povprečja posamezne vrednosti lastnosti običajno predstavljajo relativne kazalnike dinamike, zgrajene v obliki verižnih vrednosti, kot razmerje med vsako stopnjo serije in prejšnjo stopnjo.
![]() , - verižni koeficienti rasti;
, - verižni koeficienti rasti;
n je število dejavnikov rasti verige.
Če so začetni podatki navedeni na določene datume, se povprečna raven atributa določi s formulo kronološkega povprečja. Če so intervali med datumi (trenutki) enaki, potem je povprečna raven določena s formulo povprečnega kronološkega preprostega.
Oglejmo si njegov izračun na konkretnih primerih.
Primer. O stanju vlog prebivalstva v ruskih bankah v prvi polovici leta 1997 (na začetku meseca) so na voljo naslednji podatki:
Povprečno stanje vlog prebivalstva za prvo polovico leta 1997 (po formuli povprečnega kronološkega mirovanja) je znašalo.
Opis: War Thunder je vojaška MMO igra naslednje generacije, posvečena...

"Titan Siege" je obsežna spletna igra na temo skandinavske in starogrške ...

Ker sem navdušen ljubitelj videza nemških tankov, sem preživel veliko časa ...